3 FAIR principles for reproducible research
FAIR stands for Findable, Accessible, Interoperable and Reusable. Implementing the FAIR principles for data can be a challenge though. Let’s talk about how to do it in practice.
The FAIR principles are at the core of many current initiatives in research and beyond. For example the German National Research Data Infrastructure (NFDI) consortia are working on making research data (and sometimes software) FAIR. There is even a special FAIR Data Spaces project. But what does FAIR mean for you?
This chapter is based on resources from the University of Mannheim, that I recommend to check out: https://github.com/UB-Mannheim/FAIR-Data-Week. In the following I will use these and my own experience to give you a bit of a guidance on how to get started.
What are the FAIR principles for?
The FAIR principles try to help you answer the most common questions people have about data.
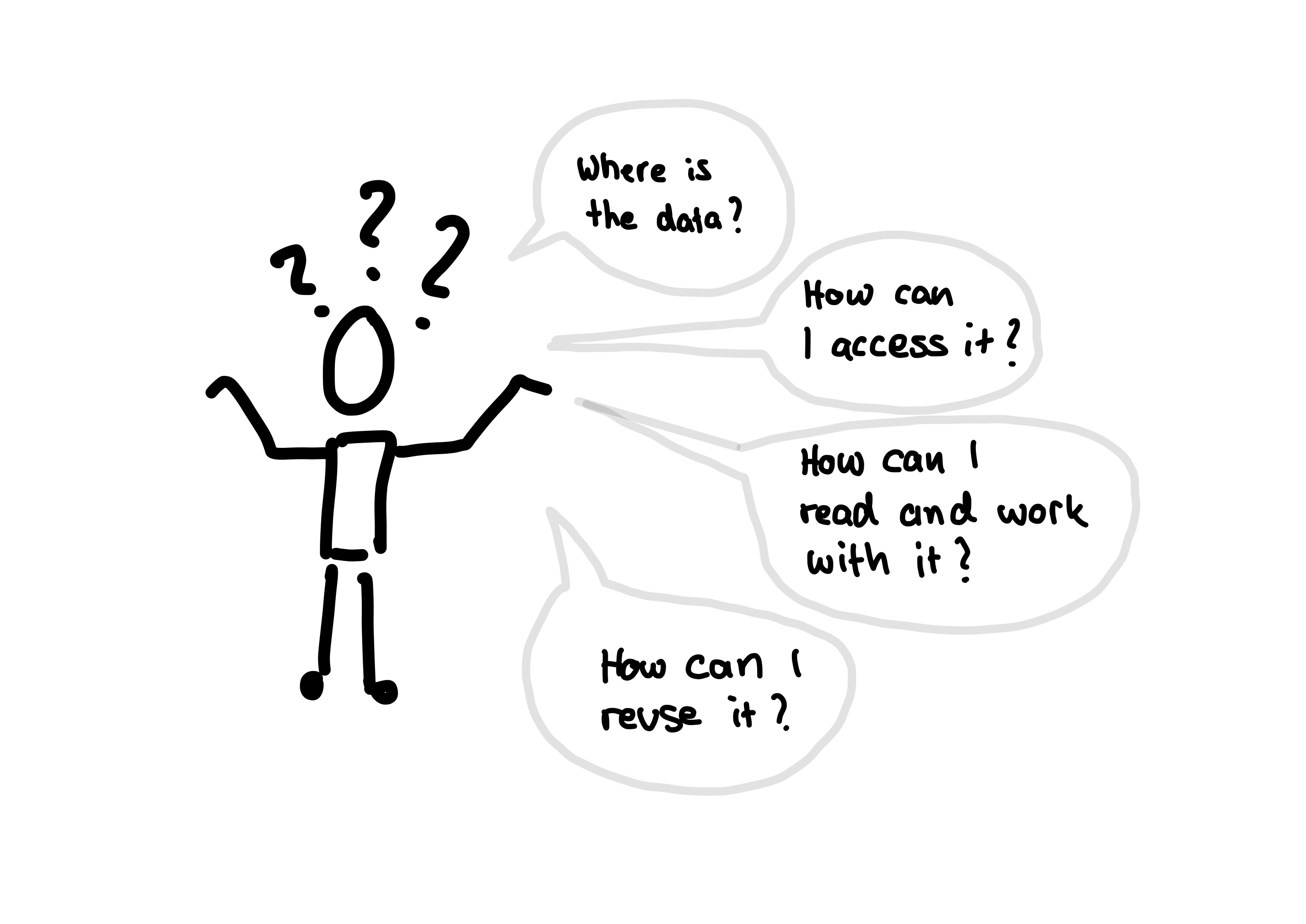
By the way, “data” in this context can mean many different things. Of course things like regular tabular data sets, but also images and other research materials.
How to get started
Store your data somewhere that makes sense. If you can make your data openly available regular data platforms such as Zenodo or the Open Science Framework (OSF) will do. Of course also field specific or institutional platforms/repositories are good options.
![]()
If you cannot make them openly available, you can usually still make the metadata available. Metadata is information about your data such as the author(s), how to cite it, what the data set contains, and so on.
Making your data known in the community increases not only your chance of creating an impact with your work but also your work’s FAIRness. You can do so by publishing a data paper or otherwise sharing more info with the community (social media, podcasts, conferences, …).
And then additionally…
F for Findable
(Three ingredients: data, metadata and infrastructure)
- Attach a DOI to your data. Many data platforms (e.g. Zenodo) make that really easy for you.
- Provide rich machine-readable metadata. If you upload your data to a good data platform, the most relevant metadata will be asked from you anyhow. So it’s easy to do things right.
A for Accessible
(FAIR is not the same as Open 👉 the point is to provide the exact conditions of accessibility)
- Explain how someone can access your data. May that be via accessing it through a data platform or through an application that is evaluated by a data-use-and-access committee.
I for Interoperable
- Use common data formats. For tabular data that could for example be csv, for images jpeg. What’s best in your community might be decided through a community standard.
- Use words that others will understand or define them. For example if the column names in your table are not self explanatory, explain them.
- Provide context for your data. Is it connected with other data or papers? You can also add your metadata to public knowledge graphs, e.g. Wikidata.
R for Reusable
- Include rich machine-readable metadata according to the community standards.
- Attach a license to your data (license is part of the metadata) that makes it clear, what others can do with your data. You can for example use the Creative Commons license CC-BY (more on how to choose a license).